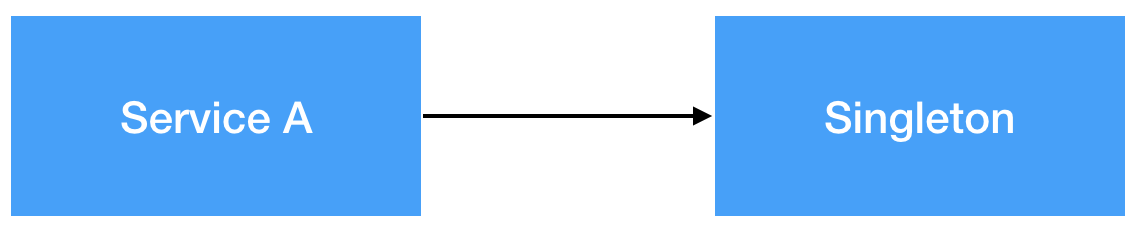Application에서 Persistent Data를 다루는 방법엔 여러가지가 있다. RDBMS를 사용하거나 단순히 txt로 저장할 수도 있고 네트워크를 통해 외부 시스템을 사용할 수도 있다. 그리고 각 저장 방식에는 메커니즘이 다르기 때문에 구현방법도 모두 다르다. 그렇기 때문에 Persistent Logic은 외부 환경과 Dependency가 매우 강하다. 따라서 Application Logic과 Persistent Logic은 섞이면 안되며 서로 독립된 레이어에 존재해야 한다. 만약 그렇지 않고 로직이 섞인 상태에서 Data Source가 바뀌게 된다면 Application Logic까지 영향도(Force)가 전달되어 변경 전파(Change Propagation)가 발생하게 된다.
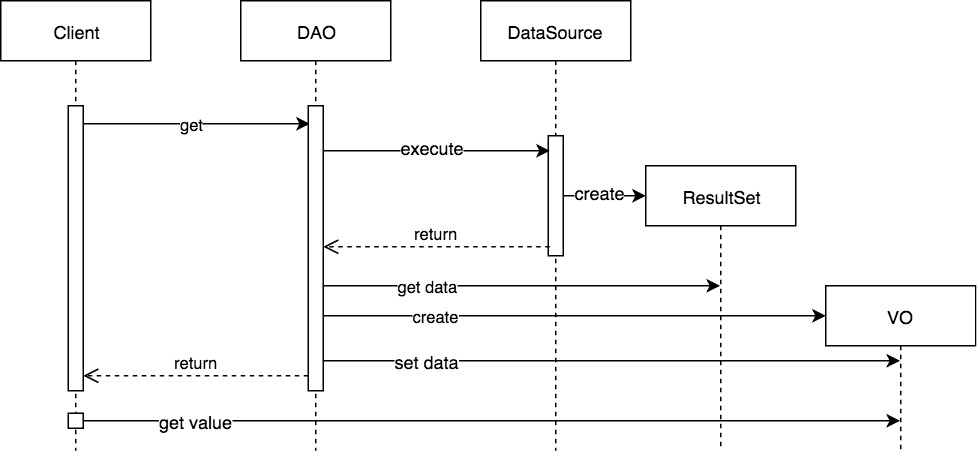
[그림 1] DAO Class Diagram
[그림 1] Data Access Object Pattern은 특정 Data Source에 접근하는 로직을 추상화하고 캡슐화 한다. DAO는 DataSource의 메커니즘을 구현하고 단순한 API만을 Client에게 제공한다. (이때, DataSource에서 사용하는 ErrorCode나 Exception같은 것도 역시 상위 레이어로 전달하면 안되며, 모두 wrapping하여 상위로 전달 해야한다.) 이제 Client에서는 DAO를 생성하고 저장해야할 Value Object를 생성하여 DAO에 전달하기만 하면 된다. 이렇게 Layer를 분리하면 DataSource가 Oracle에서 외부 네트워크 시스템으로 변경되어도 Client의 수정없이 DAO만 변경하면 된다.
[그림 2] DAO Sequence Diagram
[그림 2]는 Client가 DAO를 통해 데이터를 읽을때의 Sequence Diagram을 나타낸다. DAO는 Data Source를 통해 데이터를 읽어와서 Value Object로 변환하여 반환하고 Client를 Value Object를 통해 실제 데이터를 사용한다.
수도 코드로 예를 들면, 회원 정보를 저장하는 DAO는 아래와 같이 구현될 수 있다.
만약 Data Source와 관련된 로직을 추상화 할 수 있다면, 아래와 같이 Generic으로 추상화하여 CommonDAO를 만들 수 있다. 그렇게 되면 앞으로 생성되는 DAO class들은 정의만 하면 되고 중복 구현은 추상화 되어 없앨 수 있다. 그리고 특정 서비스에서만 사용되는 로직들만 확장하여 사용하면 된다.
Realm Instance는 thread safe하지 않으며, Realm에서 조회된 object 역시 thread safe하지 않다. Realm은 성능을 위해 무복제 아키텍쳐로 설계 되어 있다. 간단히 말하자면 realm에서 조회된 object는 단순히 database에서 복제된 data가 아니라 core database에 직접 연동되어 있다. 그렇기 때문에 조회된 object를 변경하면 database와 이미 조회된 다른 object들에 라이브로 자동 갱신된다.
일반적으로 multi threading 환경에서 critical section을보호하기위해서 Lock을사용하는데, 이는병목현상의원인이됨으로 realm에서는 lock을지원하지않는다. 따라서조회된하나의 object에여러 thread들이접근하게되면문제가발생하게됨으로만약다른 thread에서같은데이터가필요하면그 thread에서 realm instance를하나더만들고 object를다시조회해야한다.
[그림 1] 다중 버전 동시성 제어(multiversion concurrency control, MVC, MVCC)
무복제 아키텍쳐인 Realm은 ACID를 보장하기 위해서 Lock이 아닌 MVCC(multiversion concurrency control)를 기반으로 설계되어 있다. [그림 1] 처럼 조회된 object A가 변경이 있을때, realm은 스냅샷을 찍고 v2를 만들어 object가 해당 버전을 바라보게 만든다. 이때 다른 thread들이 A를 접근하게 되면 v1를 조회하게 된다. 서로 다른 버전을 조회하고 변경함으로 ACID를 보장할 수 있게 된다.
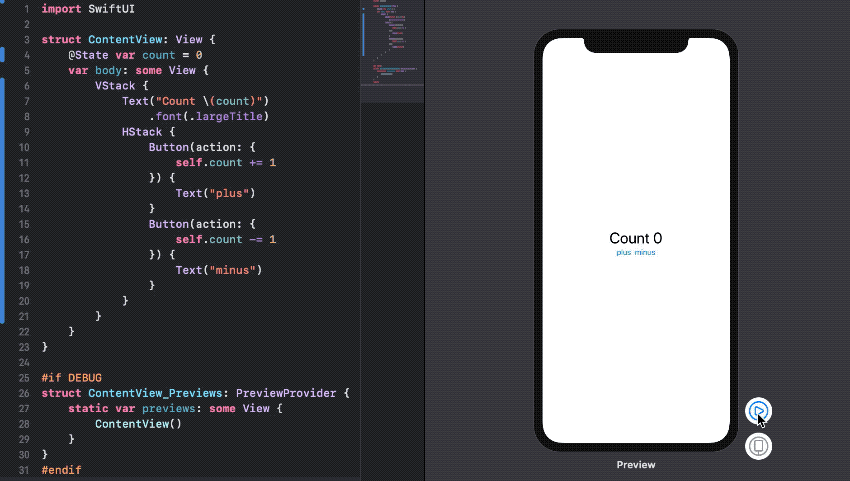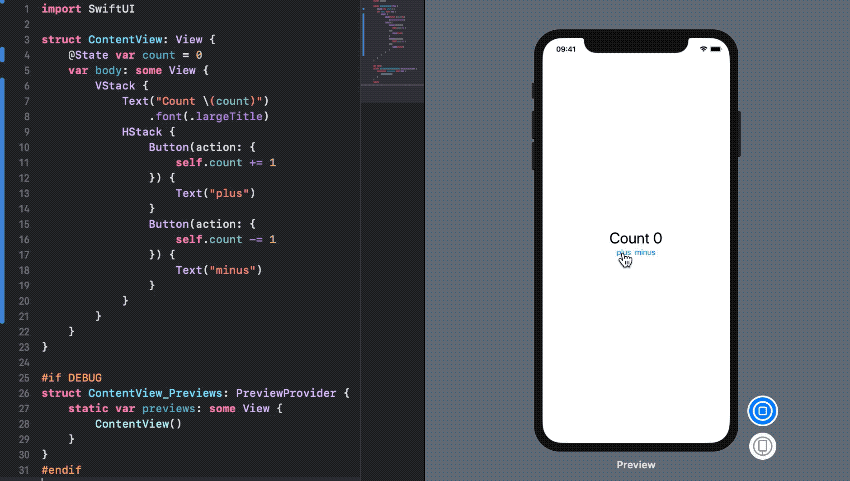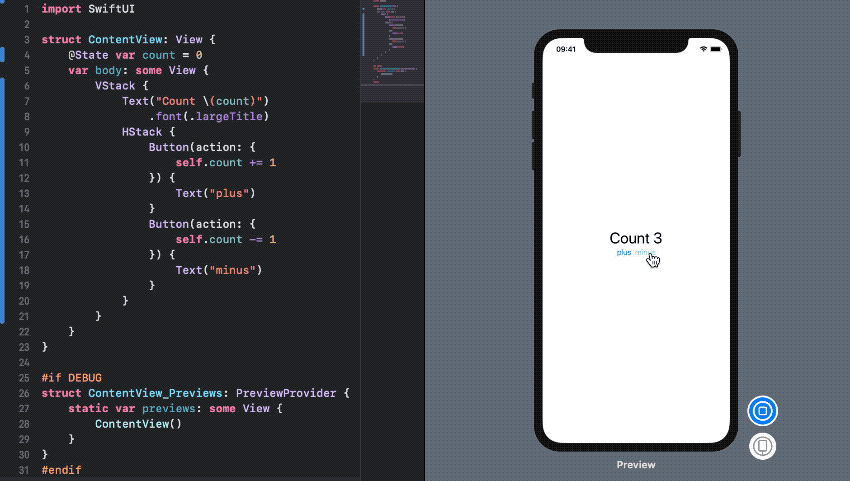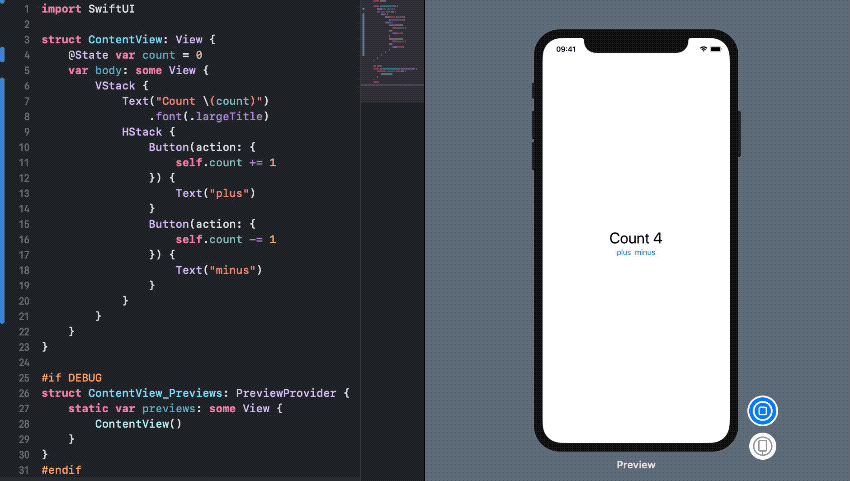
주말동안 심심해서 SwiftUI Beta를 설치해서 사용해 봤다. SwiftUI를 통해 간단한 UI를 구성해보았고, ViewController가 없어진 View가 어떤식으로 Logic을 구성하고 어떻게 Data와 Model과 관계를 맺어 동작하는지 살펴보았다.
Declarative Syntax (선언적 표현)
SwiftUI는 Declarative syntax를 사용하여 GUI를 구성한다. 예전에 Web나 React Native같은 Declarative 방식을 사용하는 프레임워크로 앱을 개발해 본 경험이 있는데, 개인적으로 GUI를 이러한 선언적 방식을 사용하여 구현하는게 내 취향에는 맞지 않았다. (여러 tool을 사용해봤지만 만족스럽지 못했던 기억이...) 그런데 SwiftUI도 Declarative 기반이라고 하여 첫인상은 썩 좋지 않았다.
경험적으로 봤을 때 Declarative 표현방식으로 구현하는 GUI는 보는 것보다 읽는 것에 비중이 크다 보니 iOS Storyboard같이 드래그 앤 드롭 방식으로 UI를 개발하는 것보다 인지적 노력이 더 필요했다. 이는 직관적이지 않음으로 내가 오래전에 구현했거나 다른 사람이 구현한 GUI를 수정하려고 할때 많은 애를 먹곤 했었다. 하지만, SwiftUI는 이러한 문제를 아래와 같이 꽤 괜찮은 GUI Tool을 통해 해결했다.
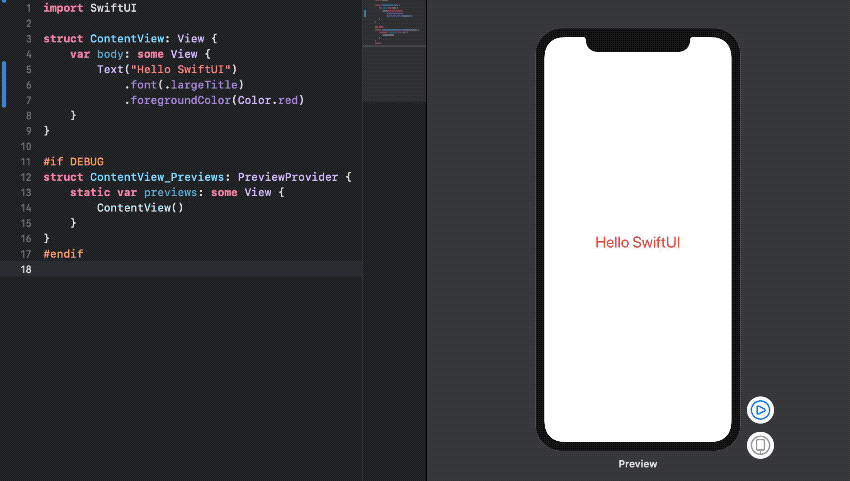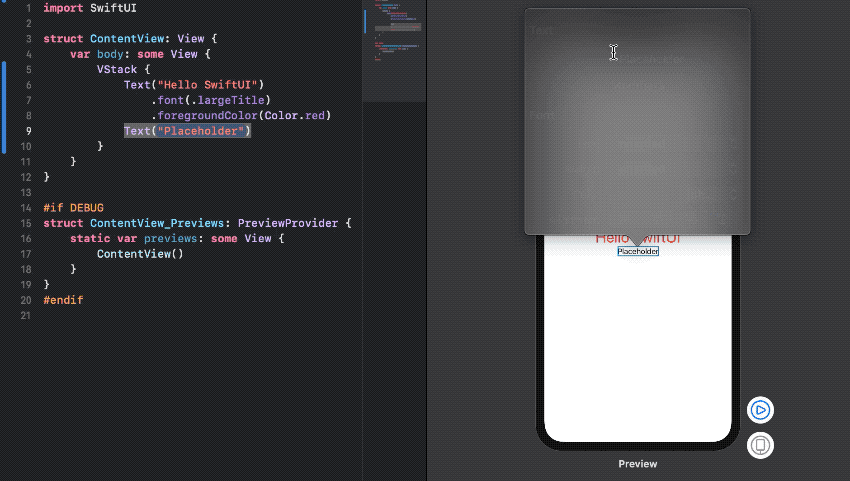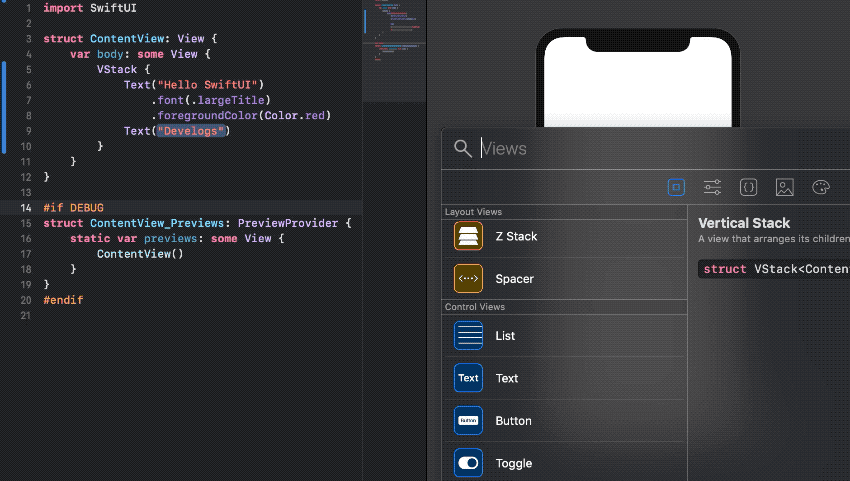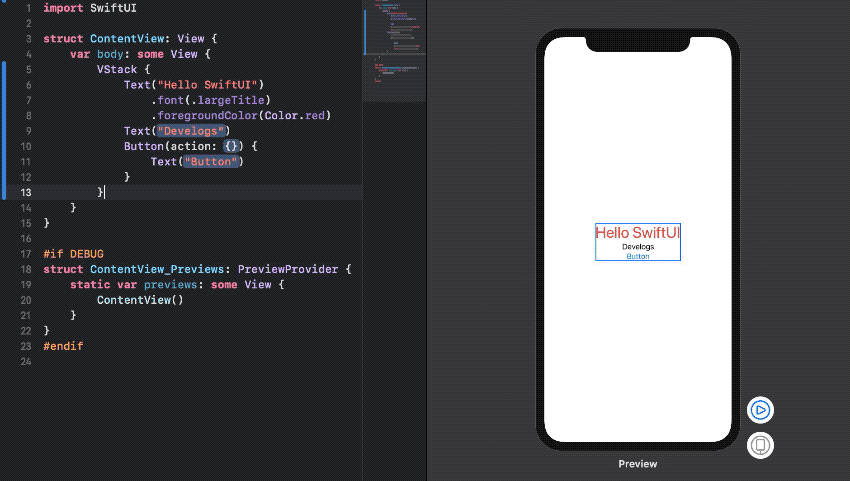
직관적인 GUI Tool
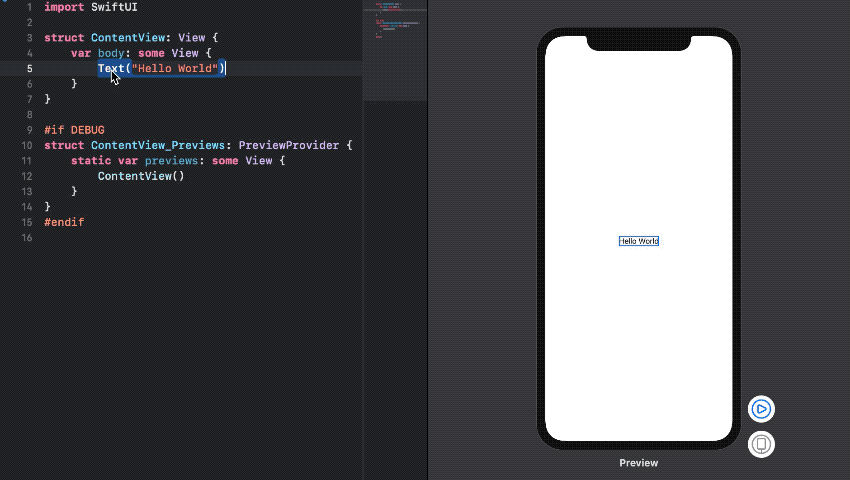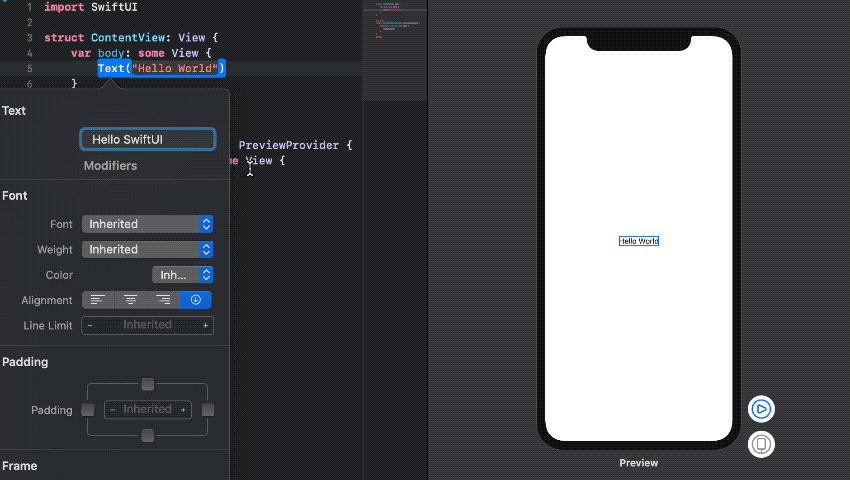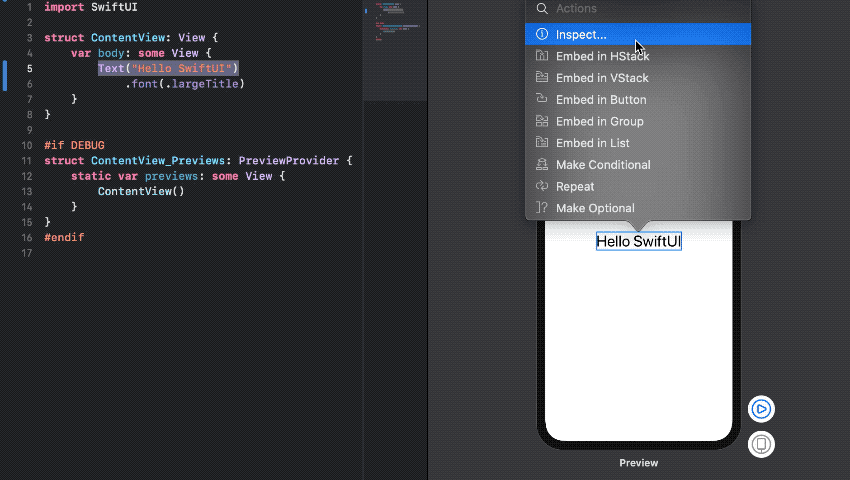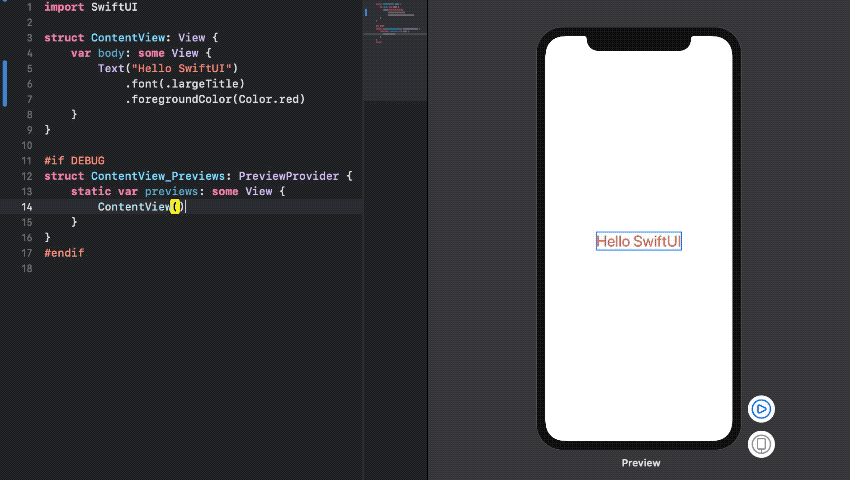
[그림 1. Inspector로 속성 바꾸기]
Code Editor 영역 혹은 Canvas 영역에서 Cmd + Click -> Inspector를 선택하면 View가 가지고 있는 속성들을 손쉽게 바꿀 수 있다.
[그림 2. Drag and Drop으로 View 추가하기]
Drag and Drop으로 View를 직관적이고 쉽게 추가 하고 수정할 수 있다. 이 기능 역시 Editor와 Canvase에서 모두 사용할 수 있다. Declarative syntax 방식의 장점과 Drag and Drop 방식의 장점들이 잘 어울러졌다.
[그림 3. Preview]
코드를 수정하면 거의 실시간으로 Preview 영역만 빠르게 컴파일하여 미리보기가 가능하다. 이는 내가 작성한 GUI의 유사한 화면을 보여주는 것이 아닌 live app으로 실제 빌드된 화면과 동일함을 보장한다.
[그림 3] 25~31 Line에서 Preview를 설정하는 부분을 볼 수 있는데, 해당 부분(28Line)에서 View가 의존하는 Class들을 Mock으로 대체하여 전달 할 수 있다. 따라서 매번 앱을 Full build하여 실제 데이터와 유저 시나리오 시퀀스대로 따라 가면서 View를 디버깅 할 필요가 없게 되었다. 이로 인해 View의 개발 및 유지보수 시간을 굉장히 절약 할 수 있을 것으로 보인다.
Two-Way Data Binding
[그림 4. State and Data Flow]
드디어 iOS에서도 Data Binding을 지원한다. SwiftUI에서 제공하는 Property를 사용하여 User의 액션이 데이터로 전달되고 변경된 데이터는 뷰를 갱신한다. 바인딩된 Property의 Memory capture(strong, weak, unowned)도 신경쓸 필요 없게됐다.
[그림 5. 기존의 ViewController]
기존의 방식에서는 유저의 액션으로 데이터를 변경하고 View를 갱신하기 위해서 UIViewController가 필요했다. UIViewController는 여러 View와 Model들을 가지고 있으며, 그 둘의 데이터 상태를 동기화 해주는 코드가 필요했다. 그리고 이런 일련의 동작들을 좀 더 깔끔하게 하기위해 우리는 꽤 많은 수고를 들여 기반코드를 작성했어야 했다.
[그림 6. SwiftUI에서의 View]
SwiftUI에서는 UIViewController가 사라졌다. View는 Struct가 되었고, 그 대신 SwiftUI는 상태를 유지하고 추척할 수 있는 @Binding, @State, @ObservableObject, @Environment등을 제공한다. 이제 iOS는 MVC가 아닌 MVVM을 사용할 수 있게 되었다.
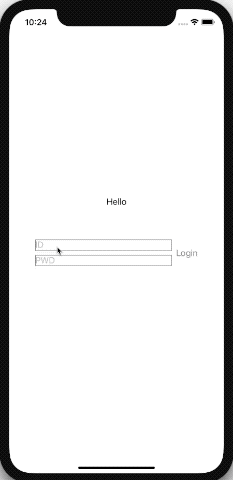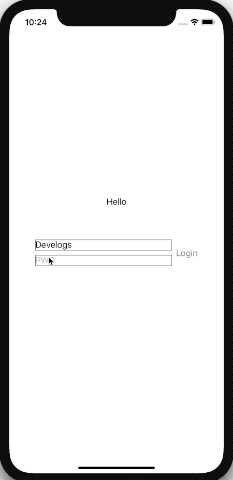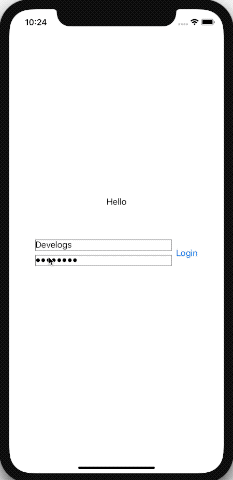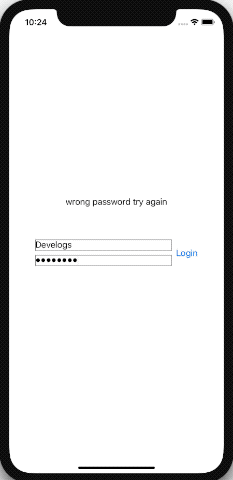
아래는 아이디와 패스워드를 입력하면 로그인 버튼이 활성화되는 테스트 코드이다. 이제 View와 Data간의 Binding하는 글루코드가 한결 깔끔해질 수 있게 되었다.
[그림 7. DataBinding]
ObvervableObject protocol을 사용하여 LoginViewModel를 만든 모습니다. @Published를 사용하여 필드를 만들면 해당 값이 변경될때마다 바인딩 된 뷰에 자동으로 값을 갱신 할 수 있다. 그리고 View에서 변경된 값이 ViewModel에도 자동으로 갱신된다.
View에서는 @EnvironmentObject를 사용하여 ViewModel를 선언하고 environmentObject를 통해 외부(22 Line)에서 데이터를 받을 수 있다. 이렇게 전달 받은 ViewModel은 위 코드에서 보이는것과 같이 손쉽게 View와 바인딩되어 사용될 수 있다.
결론
SwiftUI를 하루 정도 사용해 보았는데, Declarative과 Drag and Drop 방식의 UI구성을 적절히 잘 지원하는 것 같다. 그리고 Data Binding을 지원하게 되어 이제 MVC가 아닌 MVVM을 좀더 쉽게 사용할 수 있게 되었다.
Beta라 그런지 아직 버그가 많은것 같고, 잘못 사용한 문법 때문에 런타임에 crash가 나는 경우가 종종 있는데 로그로 충분히 crash 정보가 표현되지 못하고 있어서 좀 애를 먹긴 했다. 그리고 Apple Developer 사이트가 튜토리얼을 기가막히게 잘 작성해 놨다.
통계에 따르면 프로젝트에 존재하는 코드 중 90% 정도는 예외를 처리하는 부분이다. 그렇기 때문에 애러 처리는 어플리케이션 개발에 있어 굉장히 중요한 부분을 차지하다. 내 생각에 코드는 성공하는 로직을 위주로 작성되어야 가장 깔끔해 보인다. 일관성 있어야 하며 일반적인 제어의 흐름과 예외 처리는 분리되어야 한다. 그렇기 위해선 각 함수들의 애러는 우아하게 처리되어야 한다.
애러의 가능성을 피할 수 있으면, 해당 설계대로 작성하는게 가장 좋다. 그렇지 않다면 애러는 명시적으로 처리 되어야 한다. 아래는 rawData를 Movie list로 파싱해서 description이 있는 경우 해당 text의 길이를 더해서 반환하는 함수이다. 함수가 실패하면 의도적으로 nil(Null)을 리턴하여 해당 함수의 실패를 알리는 방식으로 코드를 작성했을때, nil을 전달 받은 getMovieDescriptionCount함수의 코드를 보자.
[nil(Null)을 사용하여 코드가 망가지는 모습]
우리가 애러 표현을 위해 습관적으로 nil을 적용 했을때 망가지는 코드의 모습이다. getMovieDescriptionCount는 예외처리 코드 때문에 성공하는 로직을 작성할 수 없다. 코드도 길어지고 가독성도 떨어졌다. nil check하는 if문이 별게 아닌 것 처럼 보이지만 최소한의 인지적 노력을 해야하기 때문에 코드를 읽는데 방해가 된다.
[애러가 정상적인 동착 처럼 보이도록 default value를 적용]
이런 경우에는 nil이 아니라 default 값을 넘기고 array인 경우 empty array를 넘겨서 정상적인 동작으로 보이도록 처리 될 수 있다. (class인 경우엔 Null Object Pattern을 사용할 수 있다.) 우리가 작성하는 대부분의 코드는 "if {성공} else {아무것도 하지 않음}" 인 경우가 많기 때문에 습관적으로 사용하는 nil 처리만 잘해도 코드가 굉장히 깔끔해 질 수 있다.
정상적인 동작처럼 보이도록 디자인 하기 어려운 경우에는 아래와 같이 여러 상태들의 조건을 확인하여 예외 처리 코드를 적용한다.
[애러를 분기 하여 예외 처리]
이 경우도 마찬가지로 if의 인지적 노력이 필요함으로 가독성이 매우 떨어지고 예외 처리 코드 때문에 코드의 일관성을 잃어 버리게 된다. 또한 2~10 line은 예외에 대한 내용이 구체적이지 않기 때문에 문제를 식별하기 굉장히 어렵다. 12~28 line은 Error Code를 정의하여 예외처리를 처리를 하였다. Error Code는 실패에 대한 명확한 이유를 알 수 있기 때문에 문제를 식별하고 구체적인 예외처리를 할 수 있다. 하지만 이 역시 일반적인 제어의 흐름 속에 예외 처리 코드가 섞여 있어서 코드의 일관성을 잃어 버렸다.
[사용자 정의 Error]
이런 경우 사용자 Error 정의하고 do try catch구문으로 처리한다. 사용자 Error의 사용은 오류를 명시적인 이름으로 정의 할 수 있으며, 오류의 가능성이 있는 함수를 사용하는 클라이언트 코드의 일반적인 제어의 흐름과 오류 처리 코드를 물리적으로 분리 시킬 수 있다. 따라서 이제 do try 블록 안에는 성공하는 로직만 존재한다.
사용자 정의 Error는 상위 레이어로 throw 될 때 OCP를 위배 할 수 있다. 상위 레이어로 오류를 전달은 wrapping하여 rethrow 하도록 디자인 할 수 있다.
Runtime에 유일한 상태를 공유하기 위해서 singleton을 많이 사용하는데, 우리가 singleton class를 만들때 기대하는 바는 위 [그림 1]과 같다. Singleton은 다른 object들과의 dependency 관계가 쉽게 맺어지고 사용될 수 있도록 구현되어 있다. 이게 singleton의 장점이자 단점으로 다가오는데, 시간이 지나면서 개발자들은 singleton이 존재해야 할 레이어에 대한 인지가 점점 떨어진다. 특히 급하게 처리되어야 할 문제들이 쉽게 해결할 수 있는 singleton으로 모이게 되는데, 이런식으로 처음 의도와는 다르게 여러 service들이 하나의 singleton을 의존하게 된다. 그리고 여러 service들에 의해 많은 기능들이 추가 되면서 점점 large class가 되어 간다. 심지어 callback을 주기위해 역참조하는 경우도 발생한다.
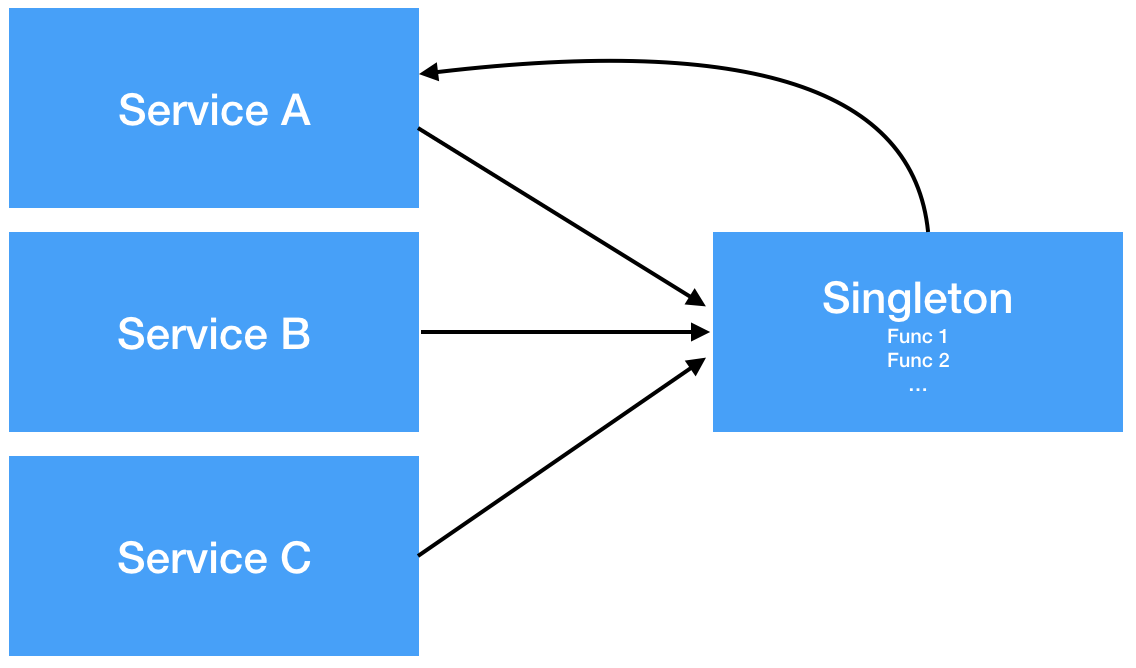
[그림 2. Large class가 되어버린 Singleton과 Dependeny rot]
[그림 2]처럼 service A를 위해 만들어졌던 func1이 다른 service들이 사용하기 시작한다. service A의 요구 사항이 변경되어 func1이 변경된다면 이를 사용하는 모든 service들에게 변경 전파(Shotgun Surgery)가 이루어진다. 그리고 이러한 coupling 문제를 개선하기 위해 singleton을 리팩토링 할 때의 영향도(Force)는 어플리케이션 전체가 된다.
Singleton은 class dependency라서 mock으로 대체 될 수 없다. 이는 singleton을 사용하는 service들의 unit test를 작성하는데 어렵게 만든다. singleton의 변경에 따른 영향도는 굉장히 높지만 그 변경에 대한 검증이 매우 부족한 상태라는 의미다.
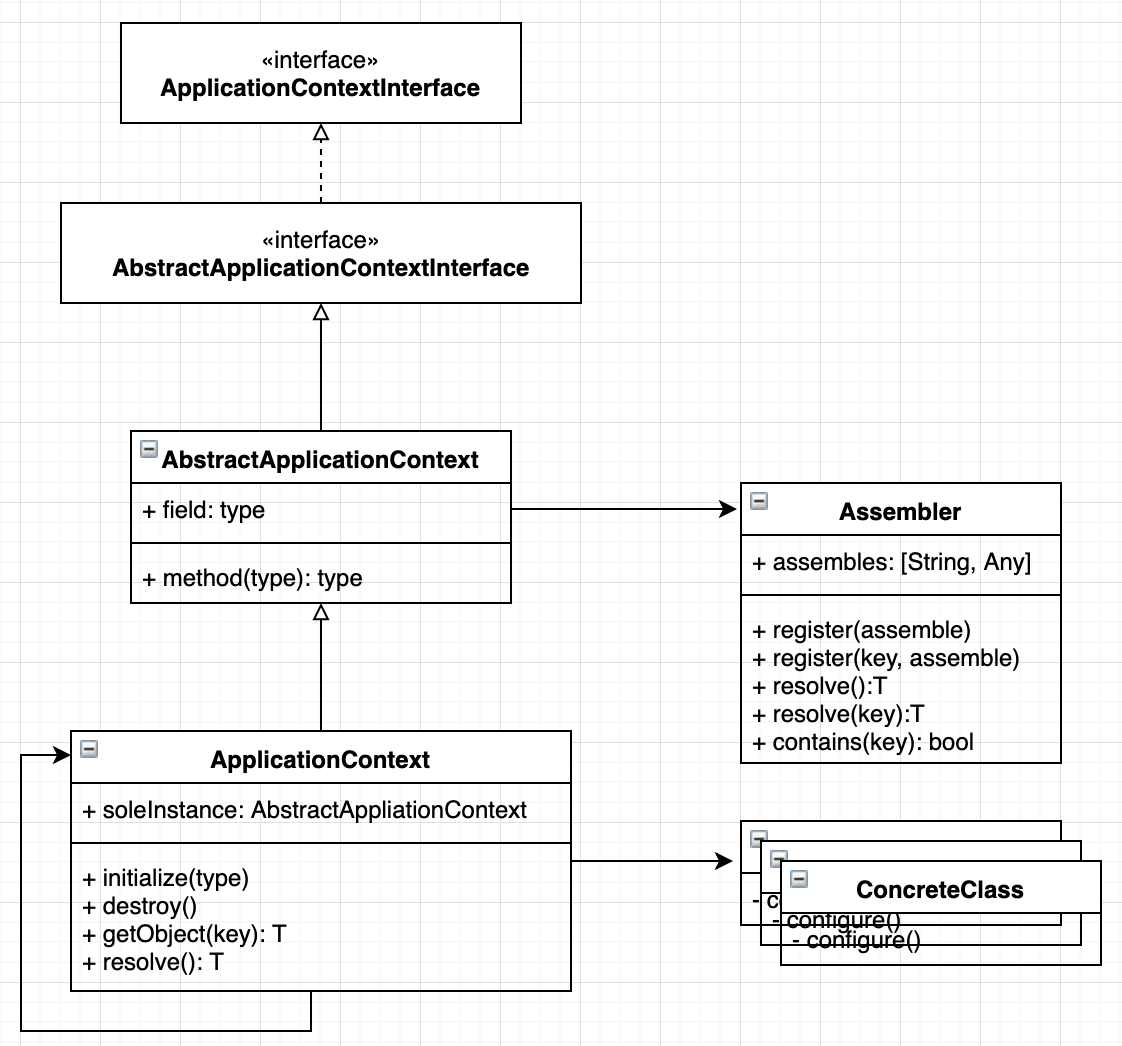
Singleton에 대한 class dependency 문제를 해결하기 위해서는 의존 관계가 외부로부터 injection 되어야 한다. 그리고 client는 이렇게 주입받은 object가 singleton instance인지 일반 object intacne인지 모르는 상태에서 사용되어야 한다. 또한 이 object는 interface에 의존하도록 디자인 되어야 한다. 이는 통제된 인터페이스를 통해 정의된 서비스를 제공하도록 디자인됨을 의미한다. 그리고 해당 object의 유일성은 Service Locator같은 녀석이 책임지고 dependency wiring은 IoC Container로부터 injection 받도록 디자인 해볼 수 있다.
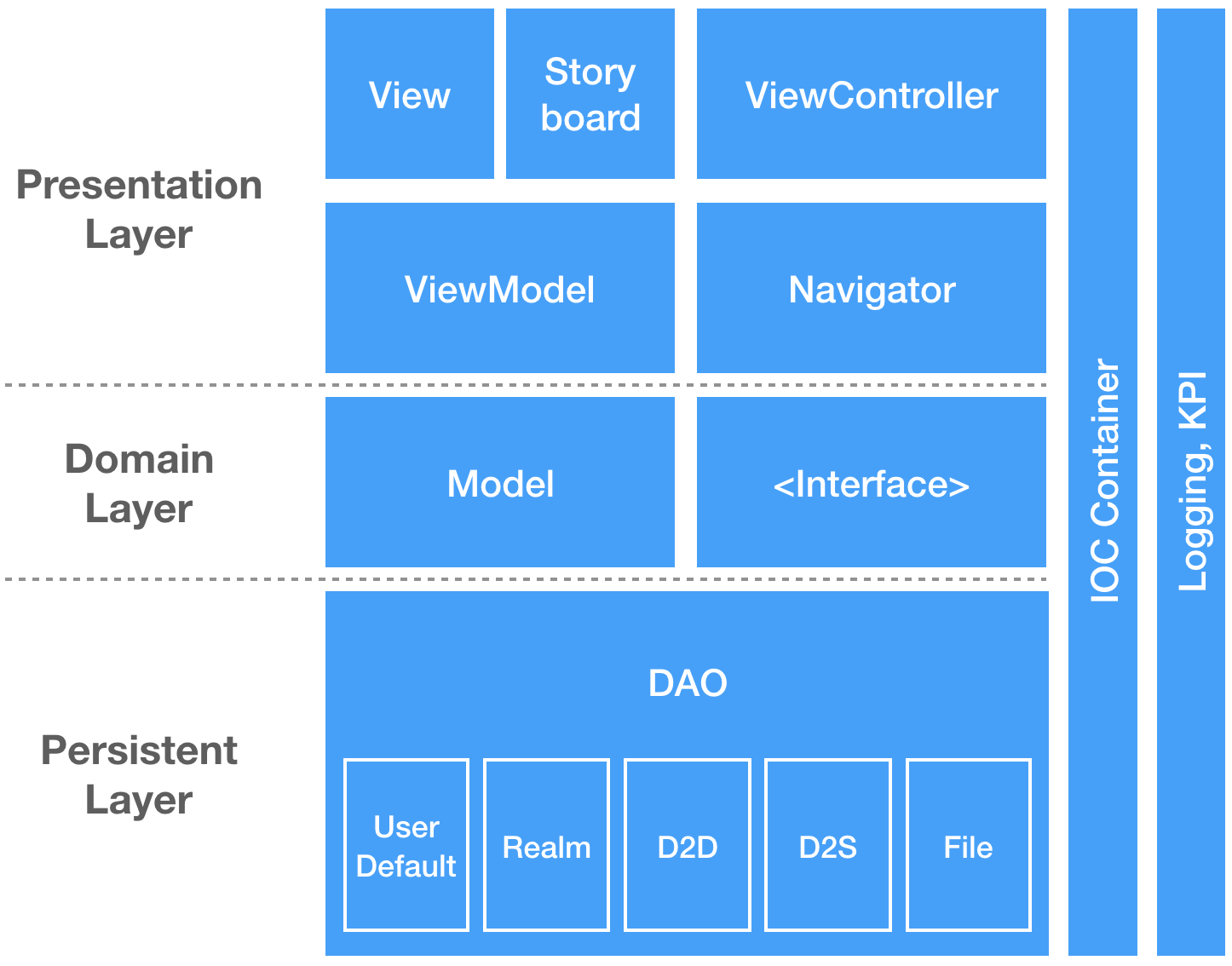
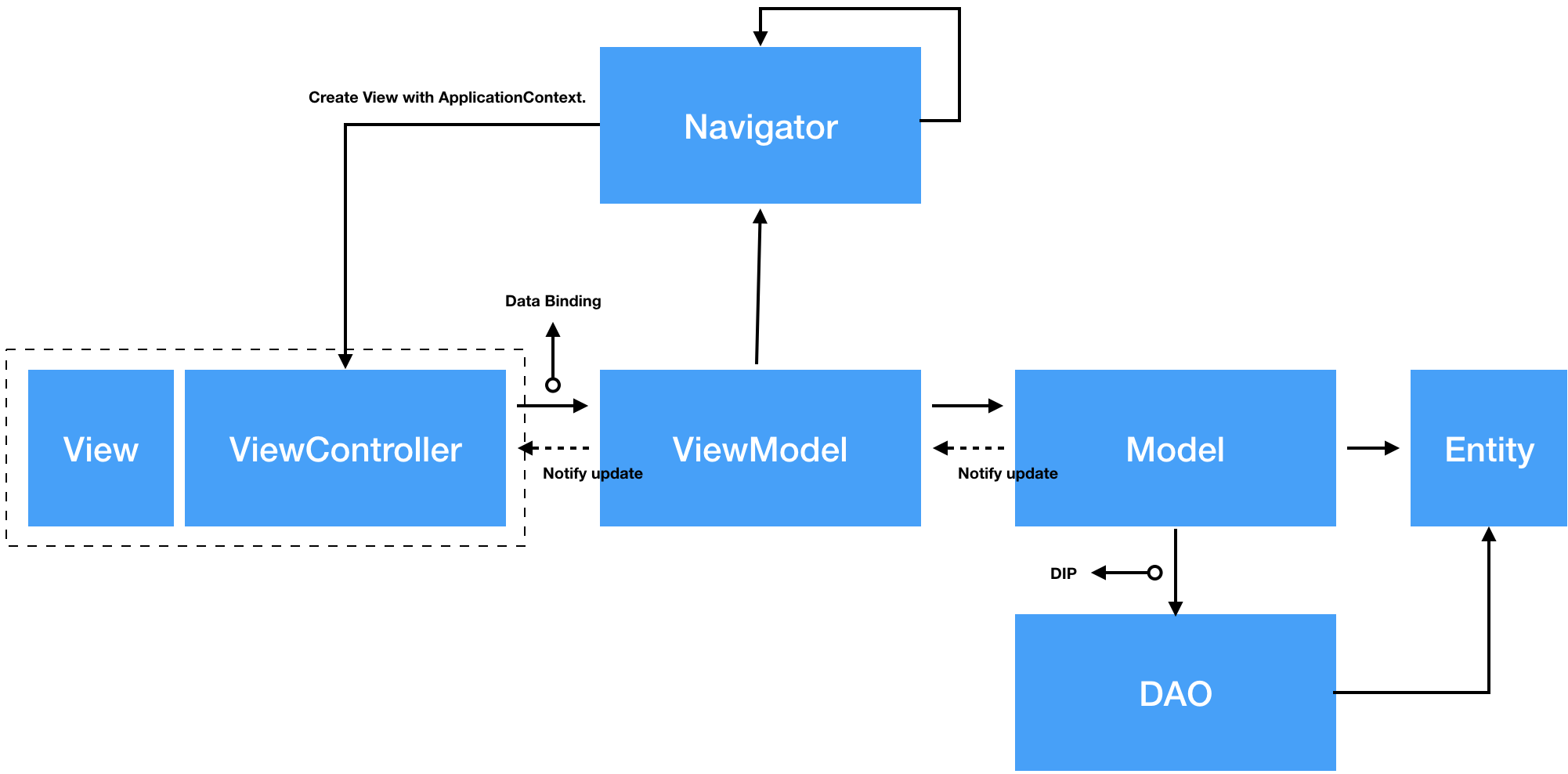
Architecture는 일반적으로 많이 사용되고 있는 3 Layer Architecture로 구성한다. 본 Architecture[그림 1]는 명확하게 정의된 레이어를 가지고 있으며, 각각의 레이어는 잘 정의되고, 통제되는 인터페이스를 통해 응집성 있는 서비스의 집합을 제공한다.
Object간의 dependency 관계는 IoC Container를 통해 injection받는다. 각 class들의 동작에대한 구성은 아래와 같다. [그림 2] 하위 레이어에서 상위 레이어로의 change propagation은 RxSwift나 delegation pattern, callback등을 통해 notify하는 방식으로 active하게 디자인한다.
[그림 2. 동작 구성]
2. IoC Container
[그림 3. IoC Container Class Diagram]
일반적인 IoC Container 라이브러리들의 무거운 기능들은 전부 제외하고 DI, Singleton지원과 같은 필수적인 기능들만 구현하여 심플하게 제공한다. (Swift IoC 라이브러리가 없어서 직접 구현함)
Object를 생성하고 각 object들간의 관계를 wiring하는 책임은 모두 IoC가 갖는다. client는 자신이 사용할 object instance를 IoC를 통해 DI받는다. 따라서 client에서는 IoC가 주는 object가 어떤 concrete class로 부터 생성이 되었는지 알필요 없으며, 정의된 interface를 통해 동작하기만 하면된다. 이는 object들간의 관계가 변경 전파 없이같은 interface로 구현된 mock나 다른 class의 object instance로 언제든 대체될 수 있음을 의미한다. IoC를 사용하여 object들과의 관계를 설정할때 되도록이면 constructor injection을 사용하는게 좋다.
[Post기능과 관련된 object들의 의존성을 구성하는 부분]
IoC(Inversion of Control, 제어의 역전)과 DI(Dependency Injection, 의존성 주입)에 대한 자세한 설명은 아래 링크에서 확인 할 수 있다.
Singleton이 필요할때는 Singleton Pattern으로 class로 디자인하지 않고 IoC에 singleton으로 register한다. clinet에서는 IoC를 통해 필요한 object가 injection되면 해당 object가 singleton인지 일반 object인지 모르는 상태에서 사용되어야 한다.
[그림 4. BaseViewController와 BaseViewModel Class Diagram]
Presentation Layer는 [그림 2]에서 보았듯이 MVVM Design Pattern을 사용한다. BaseViewController는 toast, popup, progress같은 ViewController의 공통 로직이 구현되어 있으며, BaseViewModel도 해당 ViewController와 interaction을 위한 공통 로직이 구현되어 있다. ViewController는 controller의 역할보다는 하나의 View로 보고 있으며 거기에 더해 View와 ViewModel과의 glue code가 존재하는 곳이다.
(재사용 되는 뷰가 없으면 오히려 mvvm의 기반코드를 작성하는게 이점대비 비용이 더 클수도 있다. View들의 도메인 요구사항에 따라 MVVM, MVP, MVC, VIPER등 무엇을 쓸지 design을 잘 결정하자.)
3.1 Data Binding
[그림 5. DataBinding]
View와 ViewModel은 RxSwift, RxCocoa 라이브러리를 사용하여 two way binding을 한다. ViewModel은 binding해야 될 데이터를 정의해야하며, DataBinding Interface를 통해 바인딩 전략을 구현해야한다.
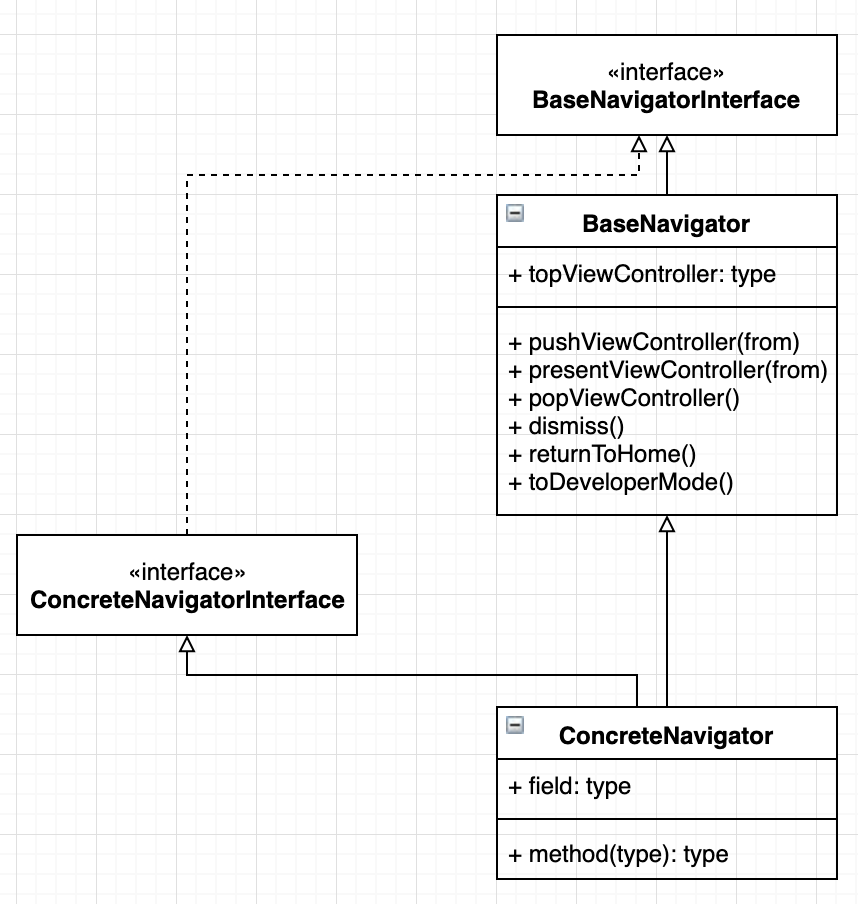
MVVM에서는 controller가 없기 때문에 Routing Mechanism이 필요한데, 그 역할은 Navigator가 담당하게 된다. Navigator는 자신이 이동해야 될 ViewController 혹은 Navigator를 IoC를 통해 전달 받아 정해진 interface를 통해 동작하게 된다.
[BaseNavigator에서 View를 받아서 present하는 부분]
4. Domain Layer
[그림 7. 상위 레이어에서 requirement를 정의하고 하위 레이어에서 concrete를 구현]
Application Logic을 담당하는 Layer임으로 Domain Layer는 반드시 다른 레이어들과 독립성을 유지해야한다. 다른 레이어들의 dependency가 존재하면 안되기 때문에 DIP(Dependency Inversion Principle)가 지켜져야 하는 레이어이다. Domain Layer에서는 필요한 requirements를 정의하고 Psersistent Layer에서는 이 정의된 requirement interface를 이용해 concrete class를 구현한다.
여기서 다루는 내용중에 Domain Layer의 isolation이 가장 중요하다고 할 수 있다. 위에서 말했듯이 Presentation Layer에서의 view design pattern은 View 요구사항에 따라 바뀌겠지만 domain layer의 isolation은 반드시 지키는게 좋다.
5. Persistent Layer
[그림 8. Dependency Inversion 되어 구현되고 있는 Persistent Layer]
Persistent Layer는 data source에 대한 decoupling을 위한 layer이며 Domain Layer에서 정의된 requirement interface를 통해 concrete class를 구현한다. Persistent Layer의 object들도 마찬가지로 IoC를 통해 Domain Layer에 injection되며, 여기서 injection된 object는 다른 구현체로 변경된다 하더라도 절대로 상위 레이어로 변경 전파가 이루어지지 않아야 한다.
6. Error Handling
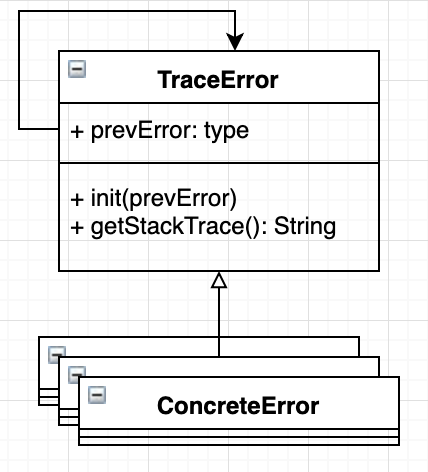
[그림 8. TraceError Class Diagram]
error stack trace를 확인하기 위해 ErrorTrace라는 최상위 error를 정의했다. ErrorTrace를 상속받아 명확한 이름을 가진 Error를 정의하고 예외는 do try catch 구문으로 처리한다.
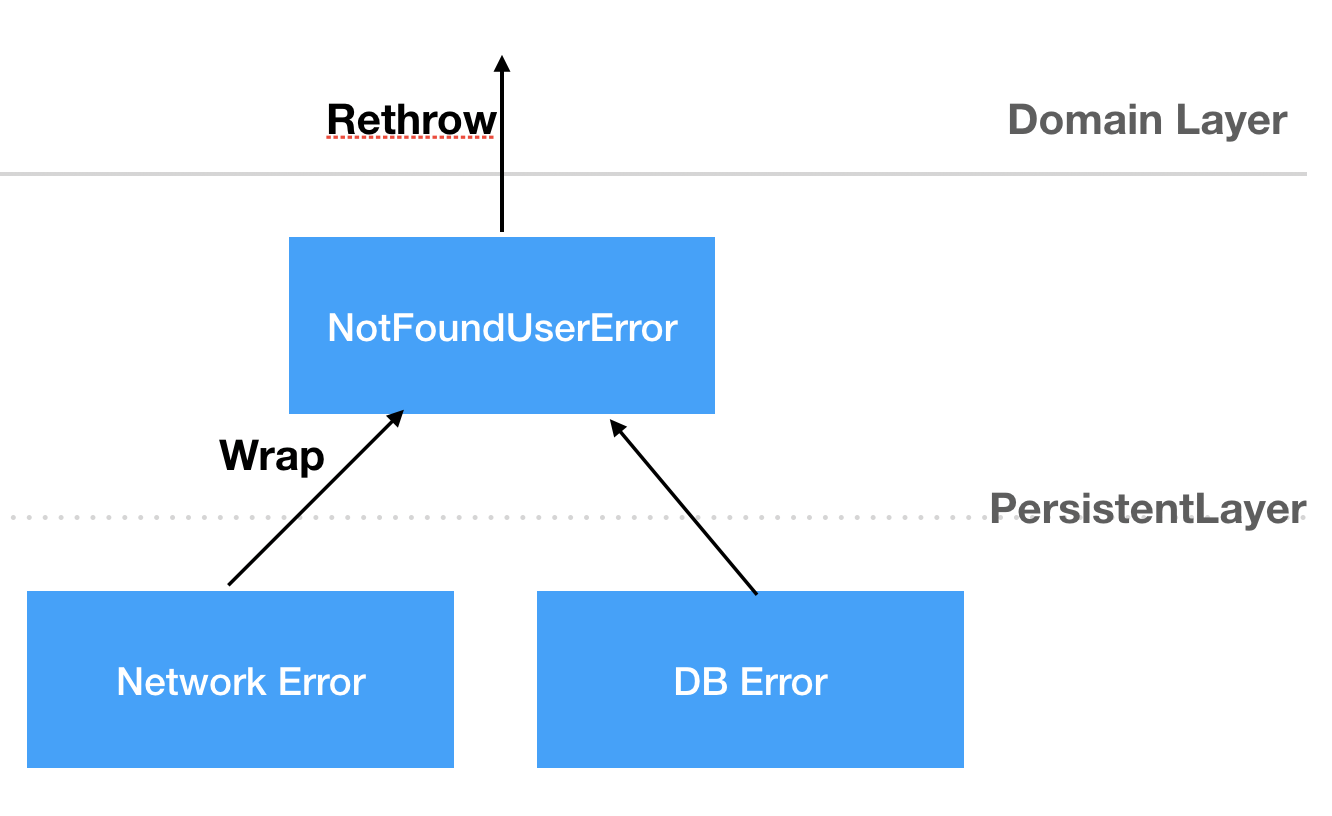
[그림 9. Error Wrapping]
error는 하위 레이어에서 상위 레이어로 thorw될 때, 상위 레이어에서 requirement로 정의된 좀 더 구체적인 이름을 가진 error로 wrapping하여 올려 준다.
getStackTrace()을 찍어보면 아래와 같이 layer별로 명확한 이름으로 정의된 error의 stack trace를 확인 할 수 있다.
🔶[ERROR TRACE]🔶
🔶 iOSCleanArchitecture/Scenes/AllPost/AllPostViewModel.swift 50: viewDidLoad() - PostInterface.LoadFailError: not found Post Data.
자바스크립트를 사용한 프로젝트를 진행했을 때의 일이다. 이미 개발된 100여 개 정도 되는 API들에 대해 몇 가지 공통적인 전/후 처리 작업을 해줘야 되는 일이 생겼는데, 누락되는 부분 없이 안정성 있게 로직이 추가되어야 했다. 당시 지급으로 처리되어야 할 급한 이슈여서 따로 라이브러리를 찾아보진 않았고 아래와 같이 간단한 AOP 모듈을 만들어 문제를 해결했다.
var AOP = (function(){
function crossCut(target, pointCut, policy){
var reg = new RegExp(pointCut);
for(var joinPointName in target){
if(reg.test(joinPointName)){
policy(joinPointName);
}
}
};
return {
injectBefore : function(advice, target, pointCut /* regular expression */){
function beforePolicy(joinPointName){
var joinPoint = target[joinPointName];
target[joinPointName] = function(){
return advice.call(target, joinPoint, arguments);
};
};
crossCut(target, pointCut, beforePolicy);
},
injectAfter : function(advice, target, pointCut /* regular expression */){
function afterPolicy(joinPointName){
var joinPoint = target[joinPointName];
target[joinPointName] = function(){
var ret = joinPoint.apply(target, arguments);
return advice.call(target, arguments, ret);
};
};
crossCut(target, pointCut, afterPolicy);
}
};
})();
AOP.injectBefore의 첫 번째 파라미터는 전처리 로직인 advice에 해당하는 함수, 두 번째 파라미터는 전처리가 필요한 target class, 세 번째 파라미터는 해당 클래스에서 전처리가 필요한 함수들의 regular expression 값이다.
function beforeLog(joinPoint, arg){ // 전처리 로직
console.log("beforeLog [" + arg[0] +"]");
return joinPoint.apply(this, arg);
};
function afterLog(arg, ret){ // 후처리 로직
console.log("afterLog [" + ret + "]");
return ret;
};
function MsgMaker() {}; // 전/후 처리가 필요한 class
MsgMaker.prototype.makeHello = function(name){
console.log("makeHello");
return "hello " + name;
};
AOP.injectBefore(beforeLog, MsgMaker.prototype, "^make"); // MsgMaker Class에서 make로 시작하는 모든 함수에 대해 전처리 추가
AOP.injectAfter(afterLog, MsgMaker.prototype, "^make"); // MsgMaker Class에서 make로 시작하는 모든 함수에 대해 후처리 추가
var maker = new MsgMaker();
console.log(maker.makeHello("world"));
//결과
/*
beforeLog [world]
makeHello
afterLog [hello world]
hello world
*/
prototype이 아닌 property로 함수를 추가했다면, 아래와 같이 .prototype을 빼야한다.